
Decentralising Storage for Web3
How to address fault tolerance in Byzantine environments


Throughout the Web 2.0 era of the Internet, the distributed systems architecture adopted by large multinational technology corporations has led to the centralisation of control over user-generated content. The financial and social implications of this information control handoff include passing corporations the power to silence or subvert large portions of the population, even entire nations. In addition to their negative impact on individual self-sovereignty, centralized systems are technically limited in many aspects, such as scalability. Perhaps their most important limitation relates to data availability and durability, as centralized systems represent, very often, a central point of failure.
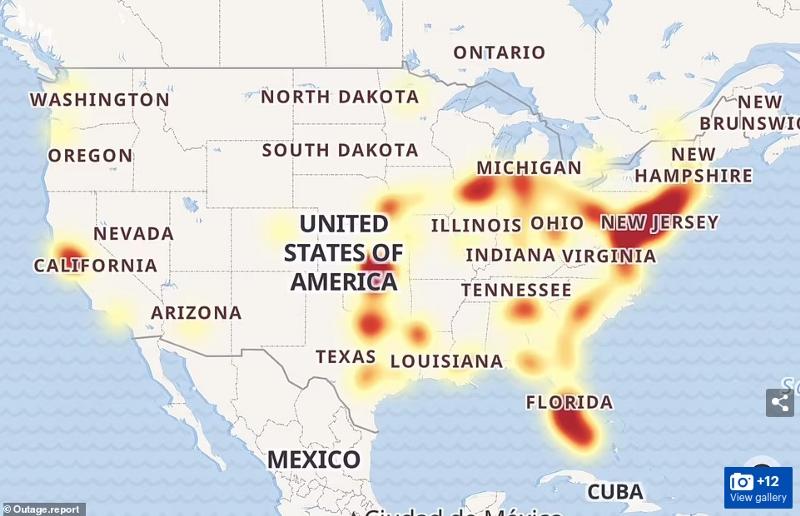
It is not news to anyone that large data centre outages are reported frequently, such as the Google cloud and Amazon S3 outages in the US-East-1 data centre region reported in 2018, 2019, 2020 and 2021. Those outages knocked offline hundreds of services, including Slack, Twilio, Atlassian, 1Password, Adobe Spark, Capital Gazette, Coinbase, Glassdoor, Flickr, The Washington Post, and many others. There is no reason to believe such events will stop occurring in the future. For this reason, it is critical that Web3 services rely on decentralised storage solutions.
NFT minting platforms offer a good case study as to why Web3 services need a decentralised storage solution. With their rise in popularity over the past year, these platforms started to realise that digital collectables are only as durable as the storage in which they persist. While NFT metadata may be stored and replicated over thousands of nodes in a decentralised manner on a blockchain (e.g. Ethereum), such metadata often points to a large file (image, music, video) that is prohibitively expensive and inefficient to store in the same manner. If the storage solution chosen for NFT bulk data may be subject to outages and censorship, or if it lacks durability guarantees, there is serious risk of NFT unavailability or even permanent loss.
Decentralised storage challenges
The fundamental property that a data storage system has to provide is data durability alongside data availability. Durability means that over a given period of time the network will faithfully store the data committed by the user. However, there are significant challenges to building a decentralised storage system that provides strong guarantees of data durability.
We can divide these challenges into two categories: i) challenges that exist for all storage systems (fault tolerance); and ii) challenges that are specific to decentralised systems where anyone can participate as a storage provider (Byzantine fault tolerance). In this article, we cover both aspects.
Fault tolerance
As with any type of electronic device, storage components are subject to failures. Studies have shown that storage data centres observe an annual failure rate between 2% and 4%. That is to say that around 2% to 4% of the disks of a data centre suffer permanent failures every year. Decentralised storage systems are usually composed of the same or even lower quality types of hardware, thus they suffer similar or higher failure rates. For this reason, it is necessary to develop schemes to avoid data loss when a disk or node in the system fails.

There are mainly two methods to protect data against failures: data replication and erasure coding. Data replication, as its name says, is a technique in which the data is replicated over multiple distant nodes so that when all nodes holding a replica fail, the replica is still present on the other node. If all nodes keeping replicas fail at the same time, the data is lost. Therefore, to be able to tolerate M simultaneous failures, it is necessary to have a total of M+1 replicas of the data in M+1 nodes.
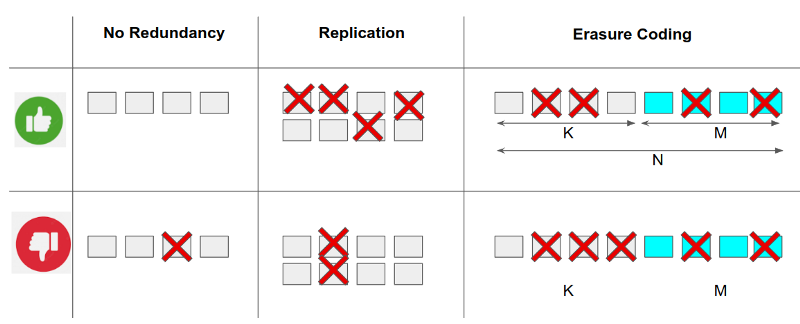
There are many types of erasure codes, with Reed-Solomon encoding being one of the most popular. To protect data with erasure coding, one first divides the original dataset into K data blocks and then uses the erasure encoding algorithm to produce a specified number of parity blocks, M.
From those K+M blocks total, data can be restored from any surviving K blocks, i.e. we can tolerate a loss of any M blocks. For example, in the case of K=M, erasure-encoded data would require only 2*S of space (S is the size of the original dataset), while replicated data would require (M+1)*S of space for the same level of protection.
Thus, erasure codes are much more space-efficient, but both the encoding and decoding are more complex and computationally expensive compared to naive data replication.
Byzantine fault tolerance
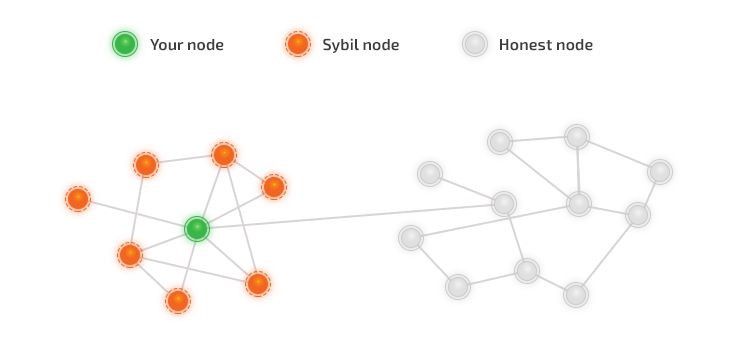
The second type of challenge is specific to decentralised storage systems where anyone, including a malicious actor, can become a storage provider. In these systems, the storage rented to users seeking to upload their files is combined from thousands of independent storage providers seeking to reap benefits from their available storage. However, some of those nodes could try to cheat the system by pretending to store more user data than they actually do. For instance, a node with 1 terabyte of storage available could pretend to store 2 terabytes of user data in order to double its profits. Another potential risk is a storage provider that creates multiple identities in the system (i.e., a Sybil attack) while actually storing all its data in the same storage component. If that provider suffers a catastrophic failure or otherwise disappears from the network, there is an increased risk that the data it stored will be lost from the network. In other words, the durability property that the system attempts to guarantee is weakened if nodes and storage components are not 1-to-1.
To avoid the above-mentioned risks, failure to store data as promised should be detectable and provable, and storage providers should be punishable if they fail to abide by agreed upon storage contracts. Each storage provider should put some collateral (e.g. some crypto) that would be lost if it does not properly fulfill its role in the network. In order to detect such failures, one can implement a Proof-of-Retrievability (PoR) system that continuously challenges storage nodes to provide cryptographic proofs that demonstrate that the data that they are contracted to store can be retrieved. Every time a storage node responds to a PoR challenge, it gains some profit. If, on the contrary, the node misses multiple sequential PoR challenges, the system can consider the node as failed and take its collateral.
Over the last decade, several decentralised storage systems have been implemented in an attempt to provide data durability and retrievability in a truly decentralised environment. However, despite advancements in problem set understanding and attempts at achieving these goals, it remains an open problem in today’s decentralised world.
Perhaps the most popular and iconic decentralised storage system is the InterPlanetary File System (IPFS). IPFS is a peer-to-peer network where nodes can store and share files with other peers. Files are content-addressed and data lookup is done with the help of a distributed hash table (DHT) called Kademlia. While IPFS implements caching-based data replication, IPFS itself does not provide any guarantees of data durability and retrievability. That is to say, one can store a file on IPFS, but the file could disappear from the network the next day.
In order to fix this issue, Filecoin was proposed as an incentive layer to IPFS to provide data durability. Filecoin implements more advanced levels of data replication to deal with random failures as well as Byzantine fault tolerance. While this is a good start, it is far from optimal, as replication is not as efficient and reliable as erasure coding.
Arweave is another project that tries to provide permanent storage in the form of a blockchain-structured storage system. The proposed methodology suffers from the same scalability issues as most blockchains, given its blockchain-like architecture.
Swarm attempts to be the hard disk of the Ethereum world computer. Incentives are implemented on top of the Ethereum blockchain. Additionally, Swarm provides censorship resistance by not allowing for deletion of data; however, it does not provide guarantees of data durability.
Sia uses data replication and encryption to provide privacy and data availability. It also offers the possibility of using erasure coding instead of replication. However, the user is responsible for enforcing the erasure coding as well as for repairing its data when some blocks of the dataset are missing. To guarantee durability, erasure coding should be a core component of the protocol.

Storj is perhaps the closest to providing data durability. It relies on robust erasure codes together with a protocol that rewards storage nodes in time intervals for the data they store and implements a well-incentivised fast repair mechanism. Nonetheless, Storj satellite nodes create some level of centralization. Studies have shown that it is possible to take down a satellite node in a test environment, making it impossible to fully retrieve some datasets while that node is offline.
Conclusions
Over the last decade, there has been substantial progress in the design and development of various decentralised storage systems. A variety of data reliability techniques have been complemented with crypto-economic incentives in order to overcome the two types of risks inherent in decentralised storage networks: Byzantine and non-Byzantine fault tolerance.
“The technical pieces required to solve the complex, decentralised storage puzzle exist already, but they live in separated solutions”
Most of the technical pieces required to solve this complex puzzle have been studied, implemented and tested in production systems. However, different components are used across different platforms, all of them with their corresponding strengths and weaknesses. Therefore, it seems there is still room for improvement.
If we combine the right pieces in the right manner, perhaps it is possible to create a more efficient, robust, reliable and fully-decentralised storage system capable of truly liberating us from existing centralized platforms.
Join the discussion with the Codex Team @ https://discord.gg/4qdQN5JaWW