
Measuring Codex Performance for Content Delivery

One of the key aspects of storage systems is download (retrieval) performance. Keeping tabs on performance and making sure we are at least on par with existing, widely deployed peer-to-peer (P2P) content distribution systems is therefore among one of our primary goals and, in that sense, Bittorrent arguably makes for an excellent baseline: it has been deployed at scale, it is fast, it has battle-tested open source implementations we can measure against, and is a well-understood system.
With that in mind, we have put together our first performance measurements in which we pit Codex against the Deluge Bittorrent client. Deluge is a well-known, libtorrent-based (rasterbar) client which can be run as a daemon and exposes an RPC API that makes it particularly convenient to control remotely. It is also written in Python, which makes it easy to script and tinker with.
The experiments described in this post are all open source and you can reproduce them in any Kubernetes cluster. You can even run them locally using Minikube if you want to, with the usual caveat that cramming dozens of nodes into a single machine will lead to very different measurements than the ones you see here as nodes contend for CPU and disk resources.
Static Dissemination Experiments
For this first round of experiments, we have set up what we refer to as a static dissemination experiment, in which we set up a static network of n nodes such that s < n of those nodes are selected as seeders, and the remainder l = n - s are selected as leechers (or downloaders). We then:
- generate a random file F of size b;
- upload F to each of the s seeders;
- ask, concurrently, for all l leechers to start downloading F;
- measure the time it takes for the downloads to complete at each leecher.
We run this simple experiment for several combinations of network size (n), file size (b), and seeder ratios (r). The seeder ratio is defined as the fraction of nodes in the network that are seeders; i.e. r = s / n. For this first batch of experiments, we have ran experiments with:
- file sizes b in {100MB, 1GB, 5GB};
- network sizes n in {2, 8, 16, 32};
- seeder ratios r of 50%, 25%, 12.5%, 6.25%, and 3.125% (depending on n).
Each combination gets repeated 10 times so we get a sense of performance variability. We also rotate the seeder set at random to account for performance differences that might arise from lack of overlay homogeneity; i.e., if you pick seeders in a large and perfectly random Erdős–Rényi graph and all nodes are equal, then it should not really matter which seeders you pick. But our networks are not large, perfectly random Erdős–Rényi graphs.
Hardware. Each node, Deluge or Codex, runs on the same hardware: a standard CPX31 Hetzner virtual machine with 4 shared vCPUs and 8GB RAM. Neither Deluge nor Codex ever use all that RAM, so it is never a bottleneck. iperf3 measurements taken across pairs of nodes in our cluster puts inter-node network speed at around 4 Gbps (Gigabits/second).
Results
Figure 1 shows the median download speed for each experiment, with the 25th and 75th percentiles drawn as error bands so one can get an idea of variability.
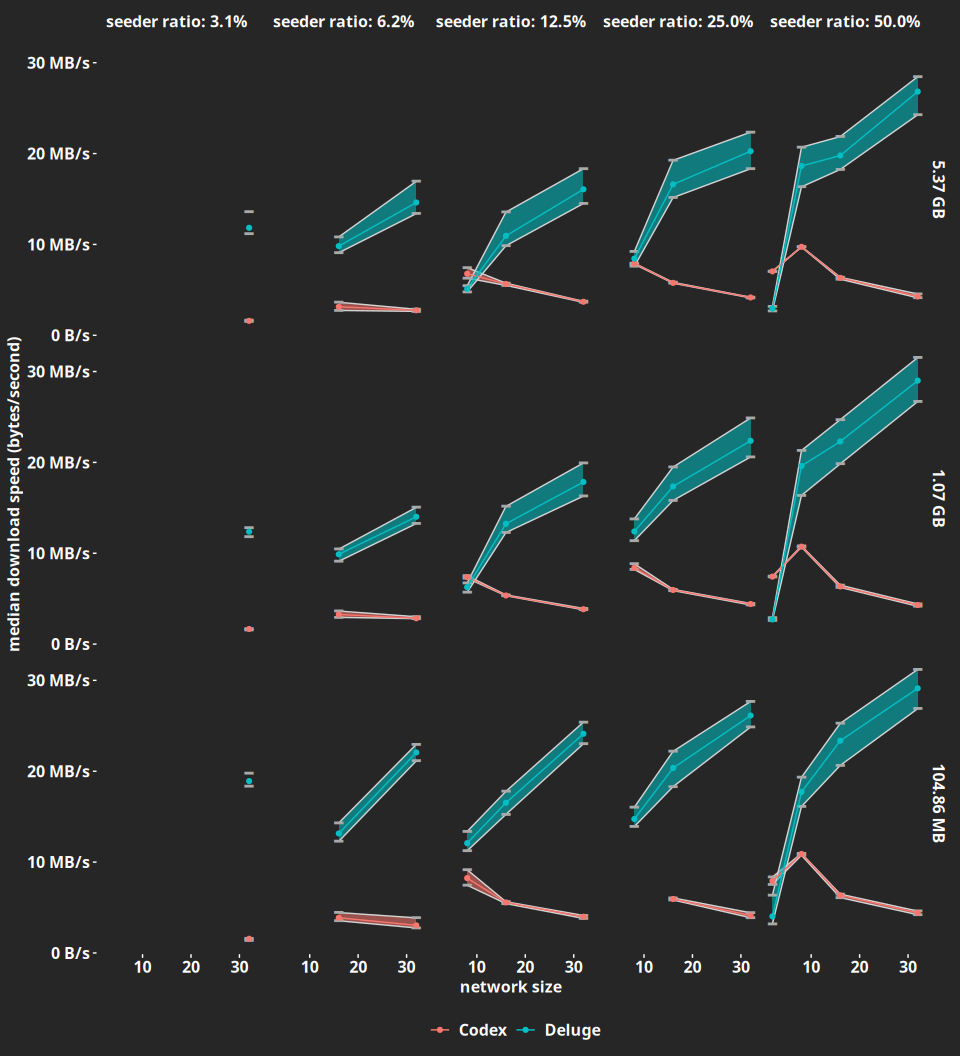
There are several interesting effects: the first is that Deluge is a lot faster than Codex, with the exception of very small (2 node) networks where Deluge seems to exhibit some performance abnormalities, likely due to the single leecher getting choked. Indeed, Deluge's download speeds are roughly between 10 to 30 MB/s (Megabytes/second) for most experiments, whereas Codex is consistently below 10 MB/s. Performance does exhibit more variability in Deluge, though, with percentiles landing farther from the medians.
Deluge also makes good use of the aggregate bandwidth afforded by larger networks, with performance increasing with network size. Codex, on the other hand, exhibits the opposite behavior, and this points out to issues in the underlying protocol which we are currently addressing. To get a feeling for just how faster Deluge is, we plotted the relative performance of Deluge with respect to Codex by dividing the median download time seen in Deluge by the one seen in Codex. The results are shown in Figure 2.
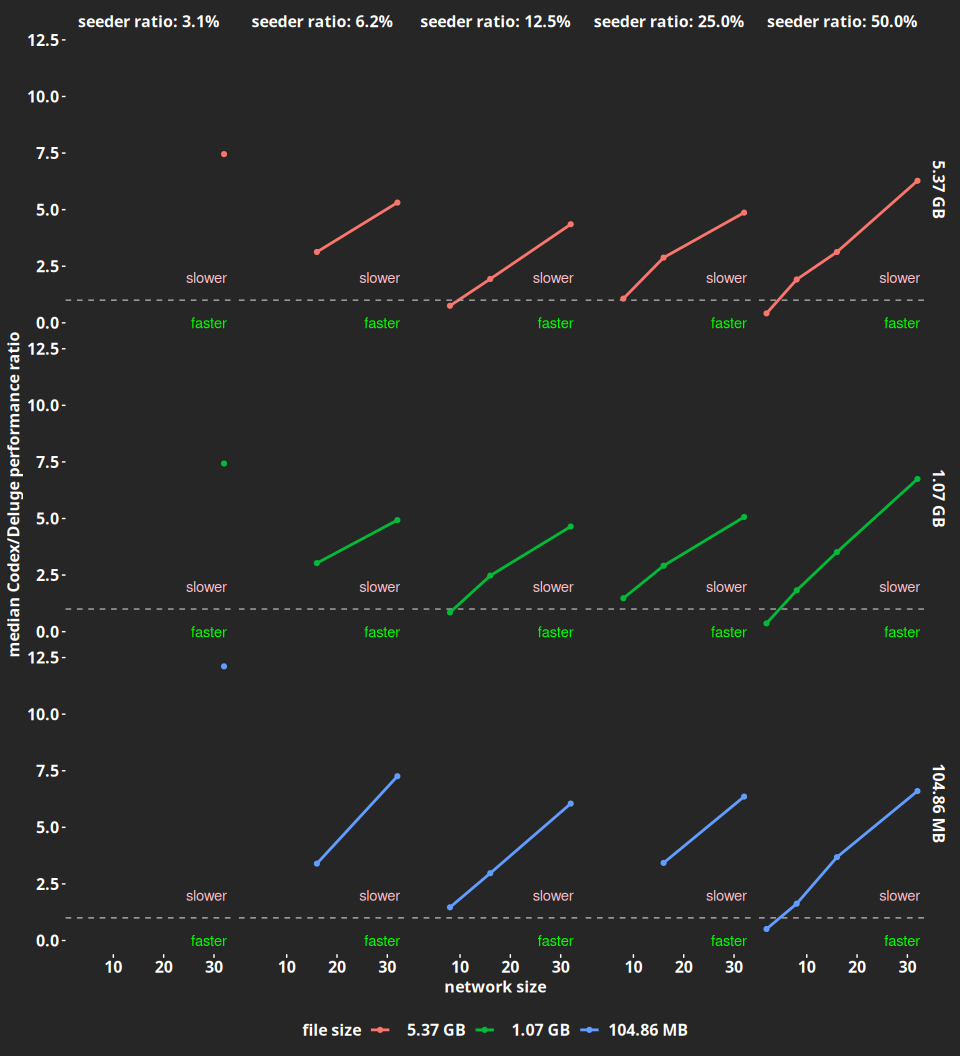
What we see is that Codex is anywhere between 2 to 12.5 slower than Deluge, with the biggest gap happening in a 32 node network with a single seeder (i.e., a 3.125% seeder ratio). The only situations in which Codex is faster is in the two-node networks in which, as we pointed out earlier, Deluge is abnormally slow. Finally, we plot the median download times with their 25th and 75th percentiles in Figure 3 for completeness. They paint a picture that is very similar to the one we had in Figure 1.
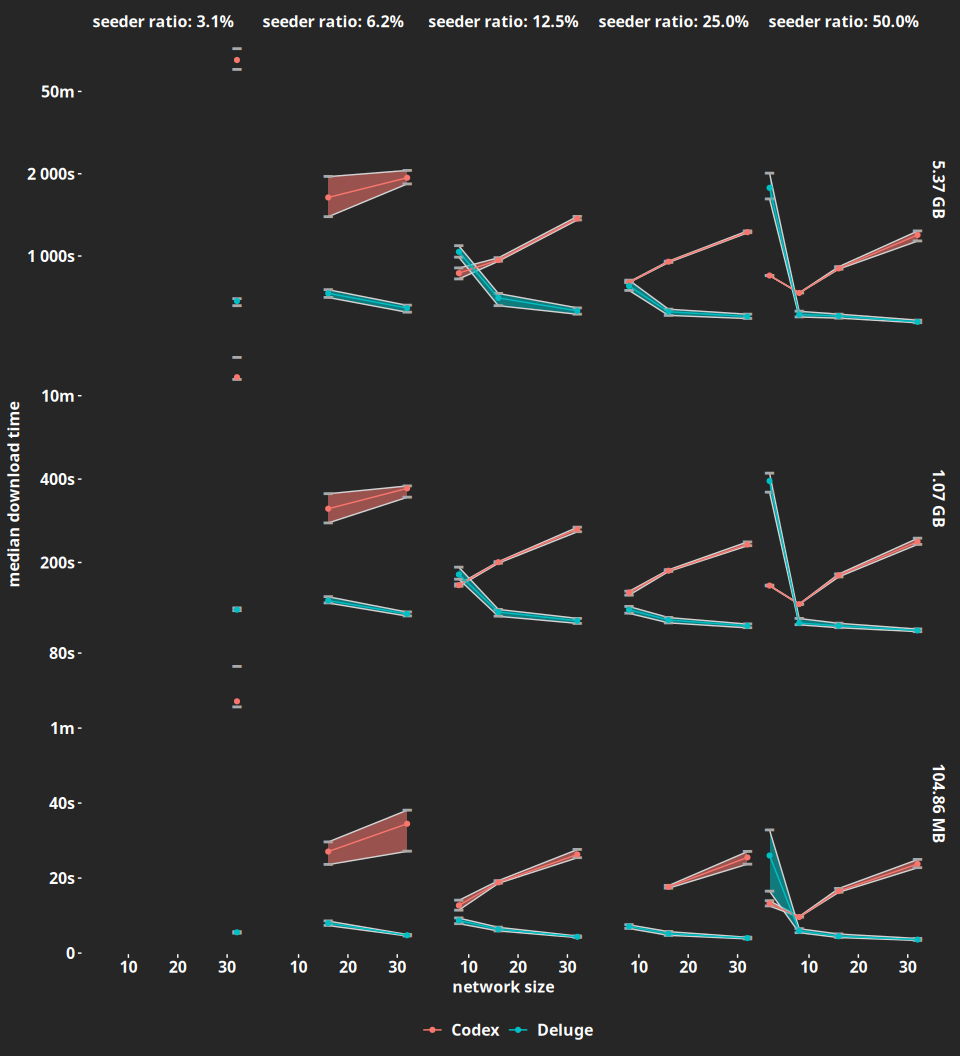
We will be working to improve those numbers in the upcoming months - our goal is to be at least as fast as Deluge - so stay tuned. If you want to check out (and download!) the exact data we got from the experiments, make sure to check out our notebook in RPubs.