
Bloated Blockchains: A Trilemma, Data Availability, and the Codex Answer


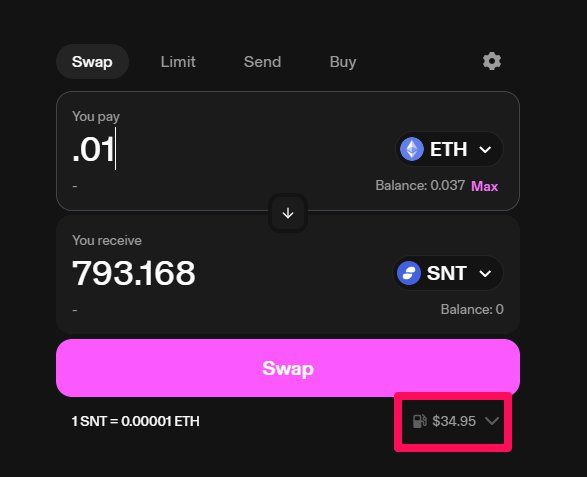
Have you ever swapped ETH for another token on Uniswap?
I connected via Metamask and tried to trade .01 Eth (roughly $35 at the time of writing) for SNT (Status Network Token). The gas fee costs as much as the transaction. That is too high of a fee to trade cryptocurrency. Most people do not want to pay this much. Wonder why these transactions are so expensive?
Web3 and decentralised finance have grown massively in recent years. Due to the rapid development and implementation of new protocols, the Ethereum blockchain has become bloated with data. The result? Prohibitively expensive gas fees and poor user experience. We can also define data bloat as 'network congestion,' where transaction data clogs the network and undermines scalability.
This article examines why the blockchain has become bloated, transaction throughput has suffered, and various approaches to solving the problem. I will specifically focus on data availability (DA) in the context of Ethereum and rollups. I will explore how Codex offers a solution with data persistence and durability guarantees that most other solutions lack.
Bear with me; I will use jargon and technical language, but I will do my best to explore this vital, underappreciated topic in clear language. More people in the ecosystem must begin grappling with how robust data availability sampling (DAS) is for scaling blockchains. Before continuing, the reader should have read about consensus mechanisms, proof of stake, and how the technology functions from a high level.
Let us start by unpacking the blockchain trilemma.
Blockchain Trilemma
All decentralised technologies that want to grow suffer from similar constraints.
They want to scale to allow more and more users to adopt the tech - from thousands to millions of users. However, scaling different technologies comes with varying engineering challenges.
In the case of Ethereum, the blocks on the chain contain transactional and smart contract data. The more people use the network, the more data is added to each block. The problem is that when the blocks start filling up, a fee market emerges, where those who pay higher gas fees are more likely to get their transaction included in the next block.
A simple solution would be to expand the block size and allow more transactional data. However, this approach has a problem, which is part of the blockchain trilemma.
The trilemma states blockchains have three primary characteristics they want to maintain and enhance: scalability, decentralisation, and security. The trilemma suggests that trying to improve two reduces the other.
In the case of Ethereum, upgrading the block capacity also increases the hardware requirements for running a fully validating node on the network. When the network raises hardware requirements this way, it becomes more difficult for ordinary people to run a full node, negatively impacting the network by decreasing overall decentralisation and censorship resistance.
On the surface, the problem seems insurmountable. Luckily, developers and engineers are rethinking how blockchains can scale. They are envisioning blockchains and their ecosystems as modular rather than monolithic.
Monolithic Versus Modular
A key ingredient to maintaining a healthy, permissionless, decentralised, and distributed blockchain network is having unique and distinct actors running a "full node."
But what exactly is a 'full node' or 'fully validating node'?
A full node is a network participant that downloads all blockchain data and executes all transactions created on the network. Full nodes require more computing power and disc space because they download the complete transactional data set.
An article by Yuan Han Li titled 'WTF is Data Availablity' explains:
'Since full nodes check every transaction to verify they follow the rules of the blockchain, blockchains cannot process more transactions per second without increasing the hardware requirements of running a full node (better hardware = more powerful full nodes = full nodes can check more transactions = bigger blocks containing more transactions are allowed).'
The problem with maintaining decentralisation is that you want some network participants to run full nodes. However, these nodes require tremendous computing power that is too expensive for most users to purchase and maintain. And if that occurs, it dramatically limits the number of nodes on the network, harming overall decentralisation.
The problem is that the validators could withhold data from the network, preventing others from accessing all the data. This is the crux of the problem in the context of 'monolithic blockchains.'
Although this is a bit of an overused buzzword in the ecosystem, the idea of 'monolithic' in blockchain means that the base layer - the Ethereum blockchain - has to act as the settlement layer, the consensus layer, and the data availability layer, which bloats the system with data, slowing down transactional throughput and raising fees.
The solution to this problem of having a 'monolithic' blockchain is to 'modularise' its functionality and offload the data availability function to other network participants. In this scenario, the base layer of the blockchain would then function as the settlement and consensus layer. Now that we understand the wisdom of modularisation, what exactly is data availability, and why is it crucial to the network?
The Data Availability Problem and Rollups
Data availability is necessary in the context of Ethereum's goals to shift towards "statelessness," where staking nodes require "near-zero" hard disk space (post-Verge and Purge workstreams being completed).
Data availability sampling as a mechanism becomes important in the context of modularising the data layer because it allows validators to efficiently and light-weight-verify data blobs (compressed transaction data from rollups) and block correctness (which is necessary when block builders may be behaving dishonestly; see Proposer-builder separation) without forcing validators to download the entire block and generate expensive commitments and proofs for the blob data. In other words, no one could prove whether the validators behaved maliciously or not.
An important aside: note the difference between 'data availability' and 'data storage.' Many people in the space require clarification on the two. Data availability asks if the data is available and anyone can access it, and data storage means holding data in a location over the long term. Nick White, Celestia's COO, provided a powerful analogy:
If you have canned food, it represents data storage. The food is in the can and stored for the long term, and can be accessed and taken out of storage at any time. Conversely, data availability is more like a buffet. The food is prepared and spread out on a buffet table. It is available for everyone to sample. Data availability is similar. Nodes make data available to the network primarily so network participants can verify the data is accurate and does not contain malicious transactions.
DA Problem Explained
So, what exactly is the 'data availability problem'?
The 'DA problem' is the central problem technologists are trying to solve to scale Ethereum. When a full node broadcasts transactional data around the ecosystem, smaller nodes called 'light nodes' do not typically have the hardware requirements to download and execute all transactions.
A ledger.com article explained how light nodes work:
'Light nodes do not download or validate transactions and only contain the block header. In other words, light nodes assume that transactions in a block are valid without the verification that full nodes provide, which makes light nodes less secure. This issue is referred to as the data availability problem.'
In this case, those nodes need to know if the data is available and if it represents the current 'state' of the blockchain. A 'state' is all the blockchain data stored on the chain, address balances, and smart contract values. On the Ethereum blockchain, in its current form, light clients have to rely on so-called data availability committees (DACs) to provide on-chain attestations that the data is indeed available.
In the context of an Ethereum scaling solution, called a rollup, this data has to be made available so that network participants can determine if that data conforms to network rules. In other words, they must ensure the data is accurate and that validators do not try to dupe the light clients.
Rollups: Optimistic and ZK
To understand the DA problem further, we must explore rollups. Rollups are layer two blockchains with nodes called sequencers; these sequencers assist in batching, compressing, and ordering transactions. Benjamin Simon described the relationship between rollups and Ethereum:
'A rollup is essentially a separate blockchain, but with a couple of modifications. Like Ethereum, a rollup protocol has a 'virtual machine' that executes smart contract code. The rollup's virtual machine operates independently from Ethereum's own virtual machine (the 'EVM'), but it is managed by an Ethereum smart contract. This connection allows rollups and Ethereum to communicate. A rollup executes transactions and processes data, and Ethereum receives and stores the results.'
Put simply, rollups are off-chain scaling solutions. However, rollups do not sacrifice security like many 'off-chain' scaling solutions normally would. In the case of rollups, only data processing and computation occur off-chain (via sequencers). The transactions are ultimately stored on the L1 blockchain (in the case of optimistic rollups), preserving security. This on-chain data was previously called 'calldata.' Interestingly, rollups are the community's way of 'having their cake and eating it too'; they get to maintain network security while scaling the network.
There are two popular types of rollups: Optimistic Rollups and ZK Rollups.
- Optimistic rollups are the more widely discussed and deployed types of rollups. As their name suggests, 'optimistic' rollups assume that there are at least 1 x n good actors in the ecosystem. What does that mean? Optimistic rollups assume all transactions posted to the network are valid. To compensate for this 'optimism,' rollups provide a 7-day window for the network to submit a 'fraudproof,' showing the transactions submitted by the rollup are invalid. One key thing to know about optimistic rollups is that they are mostly EVM compatible, so developers can efficiently work with them. In this way, they are Ethereum's more popular scaling solution. Two examples of optimistic rollups are Optimism and Arbitrum.
- ZK-rollups use zero-knowledge cryptography to prove that the transactions they compress and batch are correct and accurate. Instead of assuming that all the transactions are accurate (like optimistic rollups), ZK-rollups generate a 'validity proof' to demonstrate the transactions are valid immediately, eliminating any waiting period. However, ZK-rollups can be more difficult for developers to work with, as not all of them are EVM-compatible. ZK-rollups are also computationally intensive because generating the proofs consumes many resources. Nonetheless, more and more EVM-compatible rollups are starting to hit the market. The Scroll rollup EVM solution is just one example.
Solution: Data Availability Sampling and Codex
I mentioned earlier that rollups need somewhere to dump their data. Most rollups have been pushing data to the Ethereum main chain, leading to the problem's crux: data bloat. When bloat occurs, transactional throughput suffers, and fees for transactions and smart contract execution increase.
Recall that part of the solution is not to rely on fully validating nodes for network security. If we only rely on these nodes, most users would be unable to run full nodes due to prohibitively expensive hardware requirements. (Note that raising the block size is a potential solution, albeit dubious, as this path may negatively impact decentralisation. Nonetheless, that particular argument has become invalid because rollups act as L2 scaling solutions that maintain the security of the main chain).
What is the answer to having only some people run full nodes?
The solution is to empower light nodes (as well as full nodes) to verify data without downloading and executing all transactions. This fact is the heart of the problem and where we discover the magic of scaling the Ethereum network (among other blockchains).
Data Availability, Erasure Encoding, and Codex
The first step is to have a data availability layer with a robust network of nodes to determine if the data is available. But how can light clients, who typically only check header data and rely on full nodes for their information, ensure their data is valid and complete? The answer can be found in the concept of 'DAS.'
DAS is a method of sampling a bit of data from a chunk of data and using it to probabilistically determine if the rest of the data exists and reconstruct it. Many organisations (including the Celestia blockchain and DA layer) leverage DAS through erasure encoding and polynomial commitments. Reed Solomon codes are the popular choice among many projects. These types of polynomials look like this:
Y = a[o] + a[1]x + a[2]x^2+...+a[k]x^k
Nodes use these functions to determine missing data and fully restore it. This restoration works by creating K of M data, where K is the original data, and M is the 'parity data.' If some of the original or parity data goes missing, the node's machine leverages a mathematical function called Lagrange Interpolation to restore it. The mathematics involved are seemingly arcane to most people, but the idea is straightforward.
There are a few clear examples of erasure coding in action. The method has been used to back up scratched CDs. Erasure-encoding in CDs can reconstruct the missing bits of music due to surface damage. Satellites also leverage erasure codes if data goes missing in the vastness of space. The satellite or the CD can reconstruct missing data, adding redundant protection to both systems.
The specific scheme that Codex (and Celestia) uses is called a 2D Reed-Solomon coding scheme. Although prevalent in the crypto ecosystem, 2D erasure coding is not new. However, how it is used to solve the DA problem is quite interesting. Dr. Bautista explained how the Codex team uses Erasure Coding versus how Ethereum uses it:
'Similarly to Codex, erasure coding the original data into a more redundant and robust data structure is fundamental for the rest of the protocol to work, without it, there is no magic. In Codex, this happens inside the Codex client of the node that wants to upload the data, while in Ethereum, this happens inside the Ethereum validator of the consensus/beacon client of the node that is building/proposing the block.'
There is more to the story regarding the data's journey in Codex, but it is beyond the scope of the article. Read Dr. Bautista's piece to understand data dispersal, sampling, and the 'lazy repair' mechanisms Codex employs.
Conclusion: Codex as the Data Persistence Layer
The debate on how to scale blockchains is ending.
In the Bitcoin ecosystem, arguments have been raging on how to scale a blockchain, from increasing the block size limit to leveraging L2 solutions. The reality is that a mixture of the two is the most reasonable solution.
For instance, Codex can act as the data persistence and durability layer for Ethereum (and other blockchains), allowing the block size to grow because the network could maintain long-term archival data storage. Furthermore, the code will be able to handle data blobs post-EIP-4844, and all the data structures typically processed and stored by the execution layer client associated with what will be pruned as a result of EIP-4444. Of course, many solutions, such as data availability sampling, come into play simultaneously by modularising the network.
The good news is that these solutions will help increase the network's throughput while maintaining the security of the base layer. And what results from that? Yep, you got it: cheaper fees and faster transactions. As users of blockchains, that is really what we care most about.
One day, I can do my token swap for pennies on the dollar instead of for $35 bucks.