
Data Availability Sampling


The Codex team is busy building a new web3 decentralized storage platform with the latest advances in erasure coding and verification systems. Part of the challenge of deploying decentralized storage infrastructure is to guarantee that the data that has been stored and is available for retrieval from the beginning until the end of the contract. This requires a verification system that scrubs the data, making sure that it is indeed available.
In order to avoid a large performance overhead in the verification process, Codex relies on erasure coding and sublinear sampling. This challenge is very similar to the one Ethereum researchers are facing while trying to design the next Ethereum update, data sharding. Data sharding also relies on erasure codes and a technique called data availability sampling (DAS). Given that both projects rely on similar data protection and verification techniques, it seemed like the perfect opportunity to join forces. In this post, we explain the technical aspects of this research project.

The Mighty Shards
The term data sharding itself sounds like an arcane magic relic found in the darkest cave of an advanced dungeons and dragons (AD&D) world. Not surprisingly, shards are often used in video games, from Minecraft to World of Warcraft. But what are shards in the world of blockchain? Well, the term comes from database literature. A blockchain could be seen as a decentralized database (yeah, we know, it is much more than that, but to simplify). Therefore, we can borrow part of the terminology used in the database field.
A shard is a piece of something. For instance, when you break a glass or crystal, the small pieces that fall are called shards. Thus, data sharding is basically a fancy term that means to break something down into pieces. How is this useful for databases? Imagine you have a big database for an online marketplace that sells goods all around the world, and you realize that your server is overloaded. To improve performance you might want to distribute it on multiple servers that work in parallel. You can split the server so that partitions focus on the users corresponding to their respective slices of the regional market. Thus, you can shard the database horizontally (assuming a customer is a row). In this way, when a user makes a transaction, only the database of its region needs to be updated. It is also possible to shard a database vertically, for instance, to focus on different services for all users.
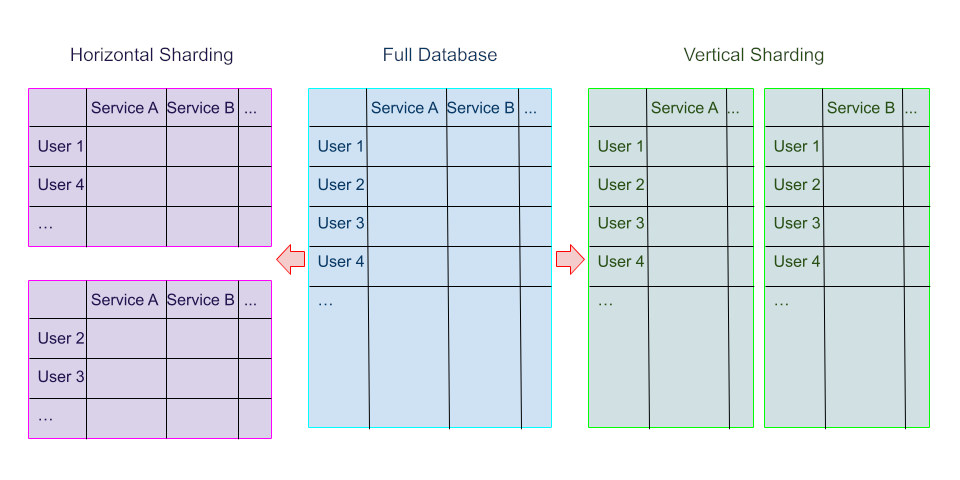
In the blockchain context, it is also possible to shard a blockchain in several ways. For instance, you could shard both data and computation, or you could shard only the data while still having the execution done everywhere. In this article, we will focus on data sharding, which is the strategy proposed by the EF for the Ethereum chain as part of a rollup-centric roadmap that has recently been nicknamed The Surge.
"Sharding data availability is much safer than sharding EVM computation."
Vitalik Buterin
Data sharding implies that not every node in the network should have all the data of the Ethereum blockchain, allowing light nodes with low storage to participate without decreasing the security of the network. However, if everybody has different parts of the data, and some nodes have only a partial view of the blocks and state, how can we be sure that no piece of the data includes fraudulent transactions?
Fraud proofs can help, but only to some extent. One could imagine an attack in which the attacker makes a fraudulent transaction, for example, to buy the Twin Blades of Azzinoth with stolen or printed money, but then does not publish some of the data (aiming to publish it later to trick someone). In this scenario, some nodes with only a partial view will not even be aware that some data is being withheld. Even worse, there is no way to prove that data is being withheld—data might be temporarily missing due to poor network conditions or transient hardware failures. Therefore, if a node receives an alert saying that data is missing and then later the node receives the data, it is impossible to determine whether the data was there all the time and it was a false alarm or whether the data was being withheld and then released after the alert was sent. This raises multiple issues and creates possible attack vectors (e.g., DoS). We invite the interested reader to get a more detailed description of this problem in this article.
To avoid this scenario, it is important to design a system that is extremely reliable, capable of withstanding multiple simultaneous failures, and guaranteeing data availability even in the face of large byzantine attacks.
The Wizard Toolbox
“Any sufficiently advanced technology is indistinguishable from magic.”
Arthur C. Clarke
Let’s see what tools researchers have at their disposal to cast such a powerful spell over data. The current Ethereum data sharding proposal makes use of erasure coding, optimized data dispersal, and data availability sampling. It is not a coincidence those are the same tools that Codex uses to guarantee data durability. In the past, we have explained how Codex makes use of erasure codes and the optimizations applied to our data verification process. Therefore, in this post, we will dive directly into the design proposed by the EF for Ethereum.
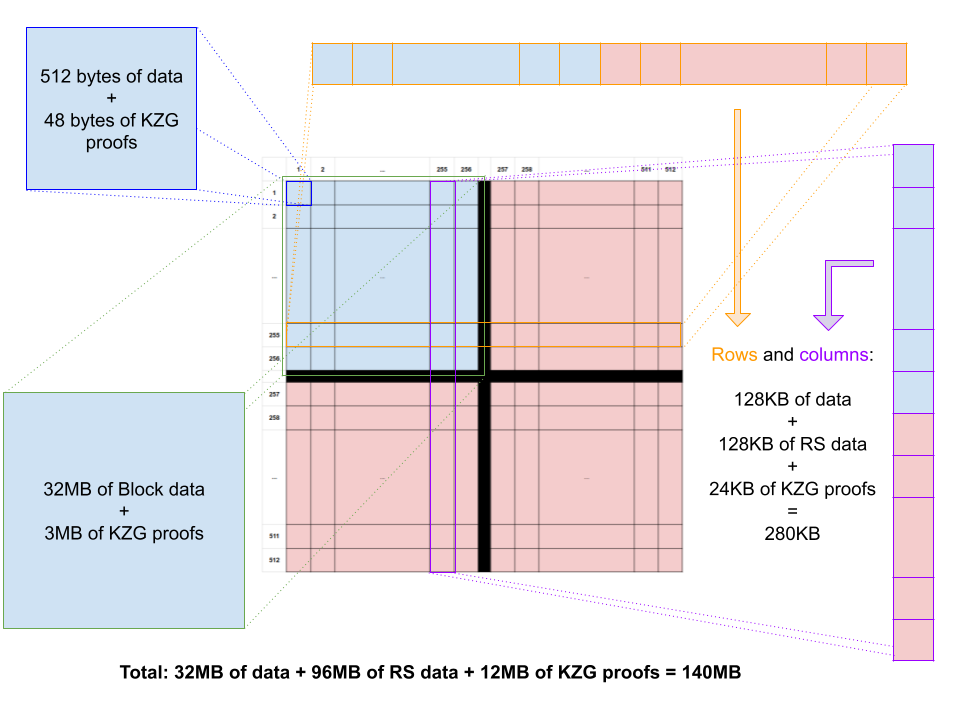
In order to increase on-chain data redundancy, Ethereum plans to use erasure codes, more specifically Reed-Solomon (RS) encoding. The idea is to lay out the data of each block into a two-dimensional array (original data in blue) and then apply RS encoding to each row and each column of the matrix. In this way, when a cell of this data matrix is lost (a data sample of 512 bytes), it can be recovered using any combination of original and parity data (in red) produced in the row where the missing sample belongs. If there are too many missing samples in that row and the row cannot be reconstructed, then the parity in the column can be used to reconstruct the missing samples. This design is elegant and offers high reliability. Two-dimensional erasure coding is not really a new technique, in fact, it is one of the oldest spells in the wizard’s compendium and has been used for over a half-century.
In the case of data sharding in a blockchain, resilience is of paramount importance. Therefore, we prefer a high-redundancy approach in which each row and column has the same amount of encoded data as the original data. In other words, if we assume the block is of size K*K, each row of size K (in blue) will produce an encoded data vector of size K (in red) as well, and the same for every column. Finally, the encoded data will also produce an extra set of encoded data (red right-bottom quadrant in the figure) that will also help repair any original data sample. The doubly-encoded chunk of data in the bottom right will help recover missing encoded samples and therefore it also helps recover missing original data samples. Assuming K=256, then the final block structure is of size 512x512 samples.
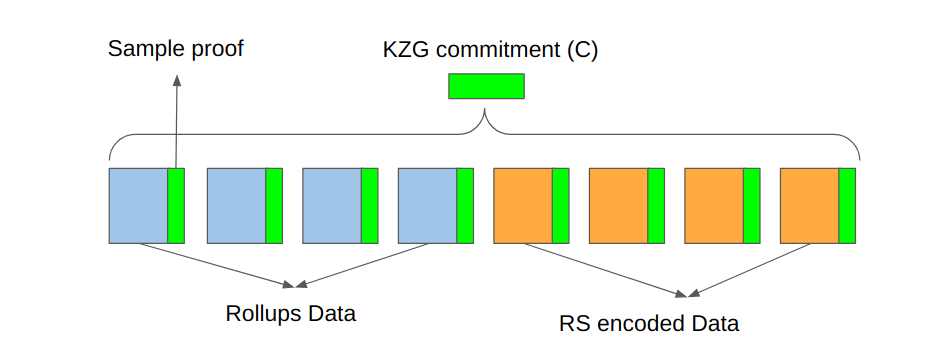
This all looks good in terms of erasure coding. However, anyone in the network, including validators, can be bad actors. The block proposer can be malicious and then disseminate garbage data instead of the erasure-coded data. Therefore, another wizard tool is needed: Kate, Zaverucha, and Goldberg (KZG) commitments.
KZG commitments allow us to easily and quickly verify that an encoded sample is indeed part of a given set of erasure-coded samples (i.e., a row or a column). The KZG proofs are about 48 bytes for each 512-byte data sample. Calculating KZG proofs for a relatively small number of samples (e.g., 512 samples) can be done fast enough, which is another reason why the 2D structure is preferred over a 1D structure where calculating the KZG commitment for a huge row will take much longer.
Similarly to Codex, erasure coding the original data into a more redundant and robust data structure is fundamental for the rest of the protocol to work, without it there is no magic. In Codex, this happens inside the Codex client of the node that wants to upload the data, while in Ethereum this happens inside the Ethereum validator of the consensus/beacon client of the node that is building/proposing the block. After the erasure-coded data structure is ready, the data starts a long process.
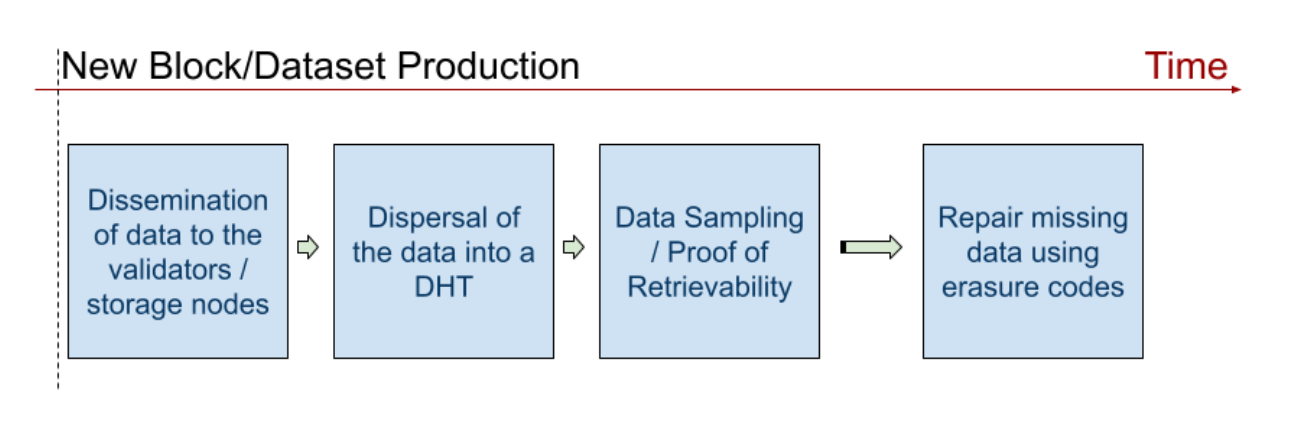
A Dangerous Journey
As any AD&D veteran will tell you, it is critical to equip your hero with the right tools, spells, and most importantly the best protection for the dangerous journey ahead—the same applies to data in the decentralized web. Once the data has been structured, erasure-coded, and is KZG-proof-ready, it starts its risky mission across the p2p network full of lazy ghosts, loud trolls, and vicious demons. This journey can be decomposed into four main steps: i) dissemination, ii) dispersal, iii) sampling, and iv) repair.
Dissemination
The first step for Ethereum data sharding is disseminating the data over a sufficiently large number of validators (i.e., nodes with a special role and collateral at stake) that are responsible for deciding if a proposed block can be added to the chain or not. To achieve this, the validators have to get a certain number χ of rows and columns and attest to the block if all the data is available and correct. The parameter χ (pronounced “chi”) has to be calibrated carefully, if it is too large the network bandwidth requirements for validators could be prohibitively expensive for solo stakers, damaging decentralization; but if it is too low the availability of the block data might be in danger too frequently.
For Codex, data dissemination corresponds to the assignment of data segments to a certain number of host providers following the erasure coding parameters given by the user. For instance, an 80 GB dataset with an 80-20 RS encoding scheme will be extended to 100GB using RS encoding and then disseminated across 100 storage nodes, each one storing 1GB of data.
Dispersal
Once a sufficiently large number of validators (usually over two-thirds of the total committee size) have positively attested to the block, then the second phase begins, which is data dispersal. Here, the samples get dispersed (not entire rows or columns) over the network so that they can be retrievable by everyone else. The dispersal includes non-validator nodes—any active node in the network with or without collateral at stake can host a number of samples. Usually, this can be implemented using a distributed hash table (DHT) in which the nodes are located over a ring (or other virtual address space) and data samples are sent to the “closest” nodes to the data. There are several ways to measure distance in DHTs, a common one is the XOR distance.
At this point, you might be wondering, why do we need to disperse samples if rows and columns were already disseminated over the validators? It is an important question. There are several reasons, but among the most important is validator protection. Today, validators on the network are kept anonymous, meaning that there is no direct way to know with certainty which validator is behind a specific IP address. Knowing the IP address of validators would open the door to a number of attacks, which is what we want to avoid. Using sample dispersal, you know that you have to contact a specific node because of its position in the DHT, not because of its validator ID. In fact, it might not even be a validator at all. In addition, those validators that hold particular data become less vulnerable to DoS attacks because there's no point attacking these nodes specifically any more—doing so will not make the data "go away".
Codex seeks data durability and not distributed validation, therefore it does not need any extra data dispersal after the initial data dissemination to the storage providers. The storage nodes that signed the smart contract and locked the collateral are the ones responsible for hosting the data. Alternatively, popular content could create a secondary market in which high-bandwidth nodes offer fast content, in addition to the storage nodes, although they are not required to host the data in the future. This could be partially similar to the dispersal process in Ethereum sharding.
Sampling
Now that data has been dispersed over the network, nodes can randomly query the DHT to try to get different samples and check whether all data in the block is available or not. DAS allows us to know that a block has a very high probability of being available if I request a number of samples and receive them correctly.
Let’s imagine that it is always possible to reconstruct the entire erasure-coded block if at least half of the samples are available. Then, we would like to verify that at least 50% of the samples can be found in the network. If we assume that the network has lost 50% of the samples and the other 50% are available, then querying a random sample to the DHT is the equivalent of a coin toss. The chances are:
* 50% head (available)
* 50% tail (not available)
If you do two random queries, the probability that both samples are available (two consecutive heads) goes down to 25%. For three random queries, the probability goes down to 12.5% and for 30 queries it goes down to 10^-9. Therefore, under these conditions, any client in the network can query 30 random samples and if all of them are available then it knows that with very high probability (i.e., 99.9999999%) the block is available. In reality, the block can be reconstructed with less than 50% of the samples in many cases, but there are some corner cases in which the block cannot be reconstructed even if three-quarters of the samples are available. Therefore, the number of queries necessary to guarantee a certain level of confidence is a bit more convoluted, but the logic is the same.
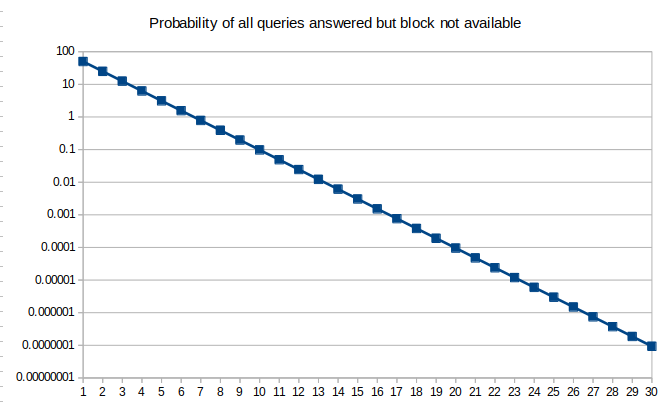
Codex also uses probabilistic sampling, although using slightly different primitives (proof of retrievability and ZK proofs) in order to make sure that all datasets are still available in their respective storage nodes. The probabilities used to compute the number of verifications necessary based on the erasure code parameters are the same.
Repair
Finally, when a sample is missing, a node can potentially trigger a repair using the encoded data of the row or column of the sample. We add this step at the end because the probability of missing data increases as time moves forward (node churn), but actually repairs can occur over different phases. For instance, validators can repair missing samples during either the dissemination or sampling phase.
It is important to highlight that the computation done to repair a row with three missing samples is the same as repairing a row with 30 missing samples. Thus, sometimes it could be beneficial to wait until a number of samples are missing before triggering repairs. Therefore, the rate at which the system triggers repairs can also be a parameter to be studied. At this moment, it has not been decided what will be the repair approach for Ethereum, so it is another open problem waiting to be analyzed in this research.
Codex shows the same opportunities in terms of data repairs. Also, similar questions arise, such as when is the best moment to trigger repairs and who should be responsible for them.
A Different Adventure
All role-playing gamers know that no matter how many times you play the same game, every adventure is different. Thus, let’s now discuss the differences between Codex and Ethereum Sharding.
- Data size: In the context of a decentralized storage marketplace, such as Codex, datasets come in all sizes, and this has an impact on the protection applied to them. For Ethereum, all blocks have a predefined size; even if they carry a different number of transactions and data, we know what to expect in terms of data size. For Codex, it would not be surprising to see 1 terabyte datasets uploaded. In contrast, we would never expect a 1 gigabyte Ethereum block. On the other side of the spectrum, small files uploaded to Codex would be also very common and they might benefit more from multiple replications rather than erasure codes.
- Arrival frequency: In addition to the size, for Ethereum, we know that a block is expected every 12 seconds. For Codex, by contrast, there is no such predictability. Datasets can be uploaded at any time, which opens the possibility of burst effects making it more challenging to handle such scenarios.
- Verification lifetime: For Ethereum, DAS is only about demonstrating that a block was initially available to the network, and it does not focus on the lifetime persistence of the blocks—that is a separate issue. On the contrary, Codex does guarantee the persistence of datasets until the end of the contract. This translates into periodic verifications for all stored datasets, which involves much greater complexity.
The Simulator
If you have made it to this point, it should be clear to you that data sharding is a complex spell and data availability sampling, in particular, is a skill that is not easy to master. For this reason, our team is building a DAS simulator to allow us to study complex scenarios and tune the many different parameters of the DAS specification. Our objective is to deeply understand what is the most performant way to implement DAS for a very large network, such as Ethereum and Codex. More of this will come in a future story.