
Scaling the Archive: Ethereum's Quest for Data Abundance


Prerequisite knowledge: Ethereum consensus, roadmap, decentralised data storage, Codex, Vitalk's Endgame paper.
"One of the points that I made in my post two and half years ago on "the Endgame" is that the different future development paths for a blockchain, at least technologically, look surprisingly similar. In both cases, you have a very large number of transactions onchain, and processing them requires (i) a large amount of computation, and (ii) a large amount of data bandwidth."
~Vitalik Buterin
Ethereum developers have spilled much ink extolling the virtues of L2s to push an insane amount of TPS (transactions per second). In a brilliant paper titled "Endgame," Vitalik Buterin states that the key to scaling Ethereum will be centralising block production and decentralising block validation. Ethereum's rollup-centric roadmap testifies to this strategy. Newer L2s like MegaETH have devised specialised L2 sequencers to maximise TPS.
This extreme scaling comes with unprecedented data storage requirements. The full chain sync size is currently over one terabyte of data. The chief concern around scaling Ethereum should be managing this data and state bloat. However, many rollups focus on utilising the base layer for data storage to take advantage of its security, immutability, and auditability, allowing them to optimise performance. Nodes will inevitably need to take on heavier data loads, but Ethereum was not built as a storage protocol.
Aside from availability concerns, the ecosystem must consider increasing archival storage capacity due to ramping up TPS. With this in mind, we need to rethink blockchain "modularisation" and include considerations around an archival data layer rather than only discussing the relevance of data availability. The network is on the verge of boosting TPS, so we must include a long-term storage, archiving, and retrieval solution. These archival needs are where decentralised storage protocols shine.
This article will examine Ethereum scaling, especially concerning TPS, EIP-4844, and archival data storage. Then, it will explore the modularisation roadmap and how the ecosystem can approach scaling the archive. Let's start here: When can we expect Ethereum to scale?
Ethereum Scalability: Execution Sharding and Danksharding
Some laypeople believed Ethereum's pivot from proof-of-work (PoW) to proof-of-stake (PoS) would immediately result in lower gas fees and higher throughput for the base layer. However, moving from PoW to PoS was merely one step. A CoinTelegraph article referenced Vitalik saying the move to PoW would help Ethereum scale. He referred to shifting Ethereum to PoS as "The Merge," which again was the first move in the scalability roadmap. The idea behind the Merge was that its original PoW functionality would become more challenging over time, incentivising miners to become validators. The Merge initiated the Beacon Chain and became final in 2022, completing the transition to proof-of-stake.
Early on, the community backed"execution sharding" as the primary method to scale the protocol. Execution sharding denotes splitting the chain into many parts that lower the resource burden on nodes. However, the Ethereum Foundation stated that it is moving away from execution sharding because rollups have matured more quickly than anticipated and have already provided scaling benefits for Ethereum. It is worth noting that Vitalik himself views rollups as a form of sharding.
Indeed, rollups decouple block production and execution from the main chain and adopt that responsibility. This new priority allows them to optimise, reduce fees, and crank up TPS. For more information on rollups, review our previous article here. The downside to leveraging this rollup-centric roadmap and L2 scaling is that it increases network data requirements and storage needs — and that data has to live somewhere. What are Ethereum's plans for managing it? The answer is danksharding.
Optimising for Optimisation: EIP-4844
Developers rolled out Danksharding during the Dencun Ethereum upgrade on March 2024 as EIP-4844. Developers referred to the first iteration as "proto-danksharding," with a later, complete sharding integration planned for the future. The phrase is named after the Ethereum researcher Dankrad Fiest.
In proto-danksharding, instead of sharding the chain or providing parallelisable computation, the network relies on receiving data blobs from rollups. Data blobs are chunks of data that are verifiable via KZG commitments. A KZG commitment is a polynomial that acts as a verifiable proof of the blob's contents. These data blobs allow for more transactional efficiency because Rollups aggregate multiple transactions and publish them to the L1. Think of data blobs as temporary solutions until full danksharding comes online.
A critical use case for data blobs is that the engineers intended them to be temporary and not stored forever. Instead, nodes prune blobs every 18 days or 4096 epochs. A key to scaling Ethereum is minimising the data bloat on the network. Previous rollup "calldata" was stored indefinitely on the base layer, diminishing efficiency and leading to data bloat. What proto-danksharding heralded was an optimisation mindset around how L2s can push significant transactional throughput efficiently. Indeed, what we are seeing now is innovation around unleashing massive TPS.
Toward Endgame: 100,000 + TPS and The Straggler Problem

An L2 called MegaETH intends to accelerate transactional throughput. The team said they can engineer for maximum TPS because their rollup prioritises node specialisation. They claim to have created the first "real-time" blockchain where users can conduct real-time transactions on Web3 with sub-millisecond latency. The idea implies that MegaETH puts blockchain processing on par with cloud computing.
However, anyone reading might quip and say there are over 40 L2 projects already. How is another going to alter the status quo? The MegaETH team responded:
"Blockchain scalability has been an active area of research for many years. So, how can we suddenly achieve performance enhancements that surpass the current state of the art by orders of magnitude? The answer is surprisingly straightforward: by delegating security and censorship resistance to base layers like Ethereum and EigenDA, L2s can explore a vast design space for implementing aggressive performance optimisations."
The team's focus on node specialisation unlocked critical optimisations that solved the "straggler problem." The problem states that when multiple nodes exist on a network, a critical mass of nodes must process a transaction before finalising it. This is another name for block time. MegaETH solved the issue by exempting full nodes from executing transactions; this is where the "specialisation" comes in.
Ethereum will likely fulfil Vitalk's "endgame" vision through innovations like MegaETH (unsurprisingly, Vitalik invested in the project). It involves a centralised sequencer that is maximally optimised for throughput. However, this increased TPS guarantees more data needs for the main chain. Interestingly, MegaETH's research paper only uses the word "data" seven times, and five times, the word is used in the context of updating the state root. The team likely assumes that the data problem will eventually be solved by danksharding or modularisation. For the time being, where will all that data live?
What About the Archive?
The assumption about where the data will live is not always clearly answered. The community focuses primarily on persisting data only over a short period. This is evidenced by proto-danksharding, which institutes temporary data storage via blobs. The community also acknowledges that the data problem will eventually be fixed by full danksharding or EIP-4444 (which implements statelessness and state expiry for Ethereum), but both are a ways away.
Currently, many rollup node operators may want to keep a full blockchain record because full nodes can — if required — execute the complete archival history, albeit this takes tremendous computational resources. Note that archival storage is unnecessary for processing smart contracts and transactions or verifying states on Ethereum.
The archive is needed for various business and historical reasons, though. Here are a few:
- Dapp Development: Without access to archival history, developing Dapps would not be feasible. Trying to access any data beyond 128 blocks will result in an error. Older blockchain info will need to be queried quickly.
- Auditing: Anyone building a service that requires auditing the blockchain or gathering historical data must query the entire chain rapidly.
- Security Analytics: Anyone conducting blockchain forensics or analysis must query the chain to retrieve historical data.
This is why Ethereum requires archival data solutions post haste. Blobs are a band-aid. They stem the bleeding temporarily. In some way, the solution is only partially real because, as mentioned, many nodes will want to keep a complete blockchain record, even if they are allowed to prune their data. Archival nodes will still be necessary for many actors in the space, especially as ecosystem and dapp development continues to grow.
Data solutions, Decentralisation, and Modularisation
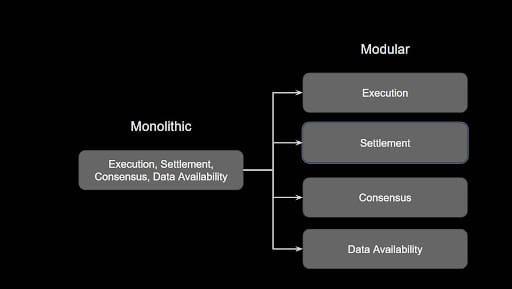
Since danksharding is years away and Ethereum is about to pursue high TPS with extremely cheap fees, the ecosystem must anticipate a prodigious uptick in data storage needs. This may not impact full nodes due to data optimisations plus pruning. However, having more decentralised options for archival data storage will help Ethereum scale indefinitely and prevent sync times from becoming untenable, negatively impacting decentralisation and censorship resistance. The higher the sync time of a chain, the less feasible it is for everyday users to run a full node, much less an archival node. This lessens overall decentralisation, another reason for the community to hyper-fixate on solving complexities around data storage.
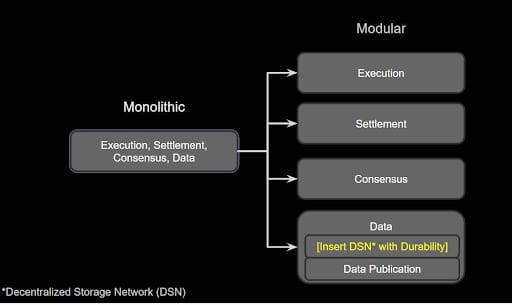
Only data availability is included in the current modularisation plans, as it is necessary for Ethereum's eventual full rollout to danksharding. However, with increasing data needs, having a decentralised storage solution is key for allowing rollups to store their data without relying on centralised or unreliable, less durable actors. This use case is one of the main areas in which Codex shines. The protocol has several primary features that mesh well with the rollup-centric road map and Vitalk's "Endgame" scenario:
- Decentralised
- Durable and persistent data
- Censorship-resistant
For more information on Codex, read the blog, explore the docs, and prepare for the testnet. Decentralised storage solutions will be vital for keeping a record of the full chain and allowing node operators to store and access it easily. Other solutions include leveraging IPFS or Portal, but these protocols have questionable data durability guarantees. They also suffer from the 1 of N trust assumption, meaning they rely on another entity's goodwill to provide that data for free.
Conclusion: Data Abundance or Data Blindness at Endgame?
In conclusion, the Ethereum community must pay attention to its emergent archival storage needs as the chain scales. Danksharding and modularisation will solve this to varying degrees, but there are still vital ecosystem use cases for archival storage, which becomes more prevalent as L2s like MegaETH come online.
Currently, "data blindness" pervades the space, with Rollup operators not always considering the implications of long-term bloat. Some in the community could construe this thinking as neglect of archival use cases. However, for data abundance to manifest at scale, the ecosystem must implement decentralised and persistent storage into the plan for modularising the chain. Without it, the industry only gives lip service to scaling Ethereum at endgame.